온톨로지란? 블루칼라 현장에 온톨로지가 필요한 이유
AI 시대의 핵심 기술 온톨로지의 개념과 기업 활용 사례, 블루칼라 현장에 온톨로지가 필요한 이유를 알아봅니다.

요즘 AI를 이야기할 때 빠지지 않는 단어가 하나 있죠. 바로 ‘온톨로지’입니다. 팔란티어의 핵심 기술로 알려지며 대중화된 개념이기도 한데요. 국내에서도 마이스터즈를 비롯한 여러 국내 기업들이 온톨로지를 핵심 기술로 도입하고 있죠. 특히 2026년 재정경제부가 국가 온톨로지를 핵심 과제로 제시하며, 기업을 넘어 국가적인 차원에서도 온톨로지에 대한 관심이 뜨겁습니다.
하지만 정작 온톨로지가 무엇인지, 어떻게 쓰이는지는 선뜻 답하기 어려우셨을텐데요. 그래서 오늘은 온톨로지의 개념부터 실제 활용 사례, 그리고 마이스터즈가 블루칼라의 온톨로지를 꿈꾸는 이유까지 정리해 보겠습니다.
온톨로지란 무엇인가요?
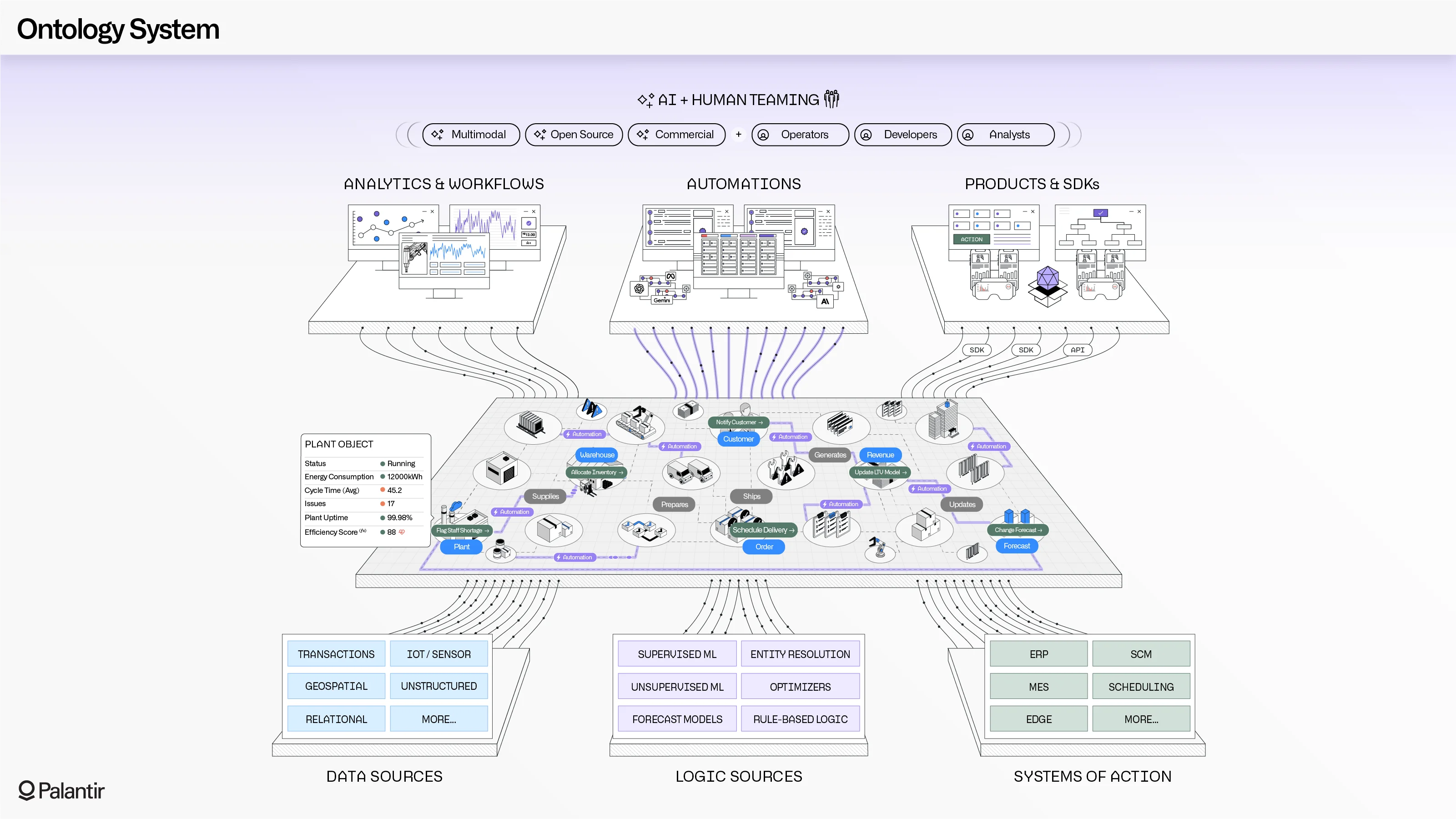
출처: 팔란티어
온톨로지(Ontology). AI 시대에 새롭게 생긴 개념 같지만 사실 2,400년 전 철학에서 탄생한 단어입니다. 그리스어로 '존재'를 뜻하는 onto와 '학문'을 뜻하는 logia의 합성어로, 존재하는 것들의 본질과 구조를 탐구하는 학문을 의미하죠. 이 철학적인 개념이 새로운 의미를 얻게 된 건 20세기 중반 인공지능(AI)과 지식공학으로 넘어오면서 부터인데요.
1993년 컴퓨터 과학자 톰 그루버(Tom Gruber)는 온톨로지를 ‘공유된 개념화에 대한 명시적 명세(An explicit specification of a shared conceptualization)’라고 정의했습니다. 좀 더 자세히 풀어보겠습니다.
개념화(Conceptualization): 일반적인 지식, 관념을 정리한 결과
명세(Specification): 개념들 간의 속성이나 관계를 명확한 언어와 기호로 정리하는 것
명시적(Explicit): 모든 개념과 관계를 또렷하게 정의하는 것
공유된(Shared): 개인이 정한 개념이 아닌, 조직 내에서 합의된 공통 기준
핵심은 ‘명시’와 ‘공유’입니다. 우리는 보통 일을 머릿속 감각으로 처리합니다. ‘이 정도면 됐지’, ‘원래 이렇게 하는 거야’ 같은 암묵적인 합의로요. 사람끼리는 이런 방식이 작동하지만, 시스템은 데이터화 되지 않으면 이해하지 못합니다. 그래서 모든 개념과 규칙을 또렷하게 적어두는 '명시'가 필요합니다.
그런데 명확하게 적어둔 문서라도 한 사람만 쓰는 것이라면 그저 메모에 불과합니다. 여러 사람과 시스템이 같은 정의를 따를 때, 비로소 데이터가 서로 연결되고 의미를 갖죠. 결국 온톨로지는 개인의 암묵지를 조직 전체가 이해할 수 있게 공통의 언어로 정리하는 작업인 것입니다.
예를 들어 가전제품, 엔지니어, 문의처럼 실제로 존재하는 대상을 데이터로 정의하고, 그사이의 관계와 운영 규칙까지 함께 담아내는 것입니다. 이렇게 현실을 데이터로 그대로 재현해 놓은 가상의 복사본을 디지털 트윈(Digital Twin)이라고 부릅니다. 예를 들어 에어컨 설치 기사가 오늘 어느 지역에서 몇 건의 작업을 했는지, 어떤 제품을 다뤘는지, 소요 시간은 얼마였는지를 데이터로 그대로 기록해 두는 것입니다.
이렇게 현실을 데이터로 복제해 두면, 실제로 현장에 가보지 않아도 지금 어디서 무슨 일이 일어나는지 파악할 수 있습니다. 현실에서 일어나는 일은 그대로 디지털 트윈에 영향을 주기 때문이죠. 단순히 데이터를 쌓아두는 것이 아니라, 조직에서 일어나는 모든 개념과 관계를 구조적으로 정의해 실제 운영까지 연결하는 것. 이것이 온톨로지의 궁극적인 목표입니다.
온톨로지의 요소 4가지
그렇다면 온톨로지는 어떻게 복잡한 현실을 데이터화하는 걸까요? 온톨로지의 작동 과정을 이해하려면 아래 구성 요소를 하나씩 살펴봐야 합니다.
요소 | 개념 | 예시 |
|---|---|---|
Class (클래스) | 현실에 존재하는 사물이나 개념의 유형 | 엔지니어 |
Instance (인스턴스) | 클래스에 속하는 구체적인 예시 | 홍길동 엔지니어 님 |
Property (속성) | 클래스나 인스턴스가 가지고 있는 특성 | 담당 지역, 보유 자격증, 숙련도 등 |
Relation (관계) | 클래스나 인스턴스 사이에 존재하는 연결 구조 | 스탠드형 에어컨 수리는 홍길동 엔지니어가 담당한다. |
예를 들어 '홍길동 엔지니어가 서울 강남구에서 에어컨 수리를 완료했다'는 현실의 사건이 있다고 해볼게요. 온톨로지는 이 장면을 이렇게 데이터로 번역합니다.
클래스 정의: 먼저 '엔지니어'라는 유형을 클래스로 정의합니다. 현실에 존재하는 대상의 종류를 시스템이 인식할 수 있게 만드는 첫 단계입니다.
인스턴스 생성: '홍길동'이라는 실제 인물을 엔지니어 클래스의 인스턴스로 등록합니다. 추상적인 유형이 구체적인 존재로 연결되는 순간이죠.
Property 부여: 홍길동 인스턴스에 담당 지역(서울 강남구), 보유 자격증, 숙련도 같은 속성값을 붙입니다. 이 시점부터 홍길동은 단순한 이름이 아니라, 맥락을 가진 데이터가 됩니다.
Relation 연결: 마지막으로 '에어컨 수리 주문 #4892를 담당한다'는 관계를 정의해 주문 데이터와 연결합니다. 사람과 업무, 제품과 지역이 하나의 구조 안에서 연결되는 것입니다.
이 과정을 거치고 나면, 단순히 데이터를 기록하는 것을 넘어, 데이터가 서로 연결된 구조로 저장됩니다. 머릿속으로만 알고 있던 현장의 정보가 시스템이 이해하고 추론할 수 있는 데이터로 바뀌는 것이죠. 팔란티어는 더 나아가 ‘Action type’이라는 한 가지 요소를 추가했습니다. Action Type은 정의된 세계 위에서 ‘실제로 무엇을 할 수 있는가’를 말합니다.
좀 더 자세히 살펴볼까요? 앞서 본 네 가지 요소는 모두 현실을 '설명'하는 데만 쓰입니다. "엔지니어가 있다", "홍길동은 강남구를 담당한다", "이 주문은 저 엔지니어와 연결되어 있다"처럼요. 즉, 현실이 어떤 상태인지 기록하고 보여줄 뿐, 그 상태를 바꾸지는 못합니다.
그런데 현장에서 벌어지는 일을 생각해 보면, 대부분 무언가를 바꾸는 행위입니다. 비어 있던 주문에 엔지니어를 배정하고, 진행 중이던 작업을 완료로 바꾸고, 끝난 작업의 비용을 정산하죠. 이렇게 데이터를 바꾸는 행위를 시스템이 처리하려면, 별도의 규칙이 필요합니다. Action Type은 바로 이런 규칙을 정의합니다.
예를 들어 '주문 배정'이라는 Action Type을 만들면 여기에는 이런 규칙이 담깁니다.
비어 있는 주문에만 배정할 수 있다
배정 대상은 해당 지역의 엔지니어여야 한다
배정되면 주문 상태가 '진행 중'으로 바뀐다
기존 데이터베이스에서는 이런 규칙이 시스템 곳곳에 흩어져 있거나, 사람이 수동으로 처리해야 했습니다. 하지만 Action Type은 이 규칙을 온톨로지 안에 함께 정의해둡니다. 덕분에 데이터를 보는 것부터 바꾸는 것까지, 하나의 시스템 안에서 모두 규칙에 따라 처리됩니다. 이렇게 온톨로지를 단순한 지식 표현 도구에서 실제 운영 도구로 확장한 것이 팔란티어 온톨로지의 핵심입니다.
온톨로지 vs 데이터베이스의 차이점
이쯤 되면 온톨로지가 단순히 데이터를 체계적으로 저장하는 ‘데이터베이스’와 무엇이 다른지 궁금하실 것 같은데요. 온톨로지가 분류 체계나 일반 데이터베이스와 결정적으로 다른 지점은 ‘추론(Reasoning)’입니다.
구분 | 데이터베이스 | 온톨로지 |
|---|---|---|
목적 | 데이터를 저장하고 조회 | 데이터에 의미와 맥락을 부여 |
구성 요소 | 테이블, 행, 열 | 클래스, 인스턴스, 속성, 관계 |
단어 해석 | 저장된 값 그대로 처리 | 도메인 맥락에 따라 의미를 해석 |
추론 가능 여부 | 불가능 | 가능 (정의된 규칙 기반으로 새로운 사실 도출) |
활용 목적 | 데이터 저장·검색·관리 | 지식 표현·AI 학습·의사결정 지원 |
데이터베이스가 데이터를 저장하는 구조라면, 온톨로지는 데이터에 의미를 부여하는 구조입니다. 블루칼라 현장으로 설명해 볼게요. 엔지니어가 작업을 마치면 지역은 '강남', 결과는 '정상', 소요 시간은 '45분'처럼 여러 값이 시스템에 입력됩니다. 데이터베이스는 이 값들을 그대로 저장합니다. 하지만 이 값들이 서로 어떻게 연결되는지, 무엇에 대한 작업이었는지는 담지 못합니다. 그저 흩어진 정보일 뿐이죠.
온톨로지는 여기에 '관계의 지도'를 그려줍니다. ‘이 작업은 강남구에서 진행된 에어컨 수리이고, 담당자는 홍길동 엔지니어이며, 수행 결과는 정상이다’처럼 값들을 서로 연결해 맥락을 만드는 겁니다. 이렇게 의미가 연결되면, 입력되지 않은 정보까지 시스템이 스스로 도출할 수 있습니다. ‘강남구에 에어컨 설치 주문이 몰리면 누구를 우선 배정해야 하는가’ 같은 고맥락의 판단이 가능해지는 것이죠. 그래서 온톨로지는 특정 산업의 데이터가 쌓일수록 더 정밀해집니다. 현장의 개념과 관계가 많아질수록 시스템이 추론할 수 있는 폭도 넓어지기 때문입니다.
팔란티어를 비롯해 이 가능성을 먼저 알아본 기업들은 이미 온톨로지를 핵심 기술로 삼고 있습니다. 그렇다면 이들은 온톨로지를 어떻게 활용하고 있을까요?

온톨로지를 활용하고 있는 기업 4가지
1. 팔란티어
팔란티어는 온톨로지를 가장 성공적으로 상용화한 기업입니다. 팔란티어의 대표적인 서비스는 ‘Foundry’라는 플랫폼으로, 기업과 정부의 의사결정을 돕는 소프트웨어인데요. 고객사 목록을 보면 미 국방부, CIA, FBI처럼 쟁쟁한 정부 기관들이 눈에 띕니다. 이들에게는 한가지 공통점이 있습니다. 데이터가 없는 것이 아니라 오히려 너무 방대한 데이터를 가지고 있어 제대로 활용하지 못한다는 것이죠. 팔란티어는 이를 온톨로지로 해결합니다.
대표적으로 미 해군 사례가 있습니다. 핵잠수함 정비는 수십 개의 조선소, 수백 개의 협력사, 수만 개의 부품이 얽힌 작업인데요. 기존에는 각 조선소와 협력사의 데이터가 따로 관리되어, 공급망 지연이 발생해도 전체 정비 일정에 어떤 영향을 미치는지 즉각적으로 파악하기 어려웠습니다.
팔란티어는 이를 해결하기 위해 2025년 12월 미 해군과 4억 4,800만 달러 규모의 계약을 맺고 'ShipOS(Shipbuilding Operating System)'를 출범시켰습니다. ShipOS는 조선소·협력사·정비 시스템 전반의 데이터를 온톨로지로 통합한 프로그램입니다. 특정 부품의 공급이 지연되면 시스템이 정비 일정과 자원을 자동으로 재배치하는 구조죠. 그 결과, 잠수함 일정 계획 수립 시간이 기존 160시간에서 10분 이내로 크게 줄었고, 자재 검토 시간은 수 주에서 1시간 이내로 단축됐습니다. 같은 예산으로 더 많은 전략 자산을 현역 상태로 유지할 수 있게 된 것이죠.
2. 구글
2012년 이전까지 구글 엔진은 텍스트를 처리하는 방식이었습니다. '에어컨 출장 수리'를 검색하면 단순히 해당 문자열이 포함된 페이지 목록을 보여줬죠. 하지만 '기사'가 현장 엔지니어인지, 뉴스 콘텐츠인지, 중세 기사(knight)인지 그 맥락은 구분하지 못했습니다. 구글은 이 한계를 온톨로지로 해결했습니다. 2012년 지식 그래프(Knowledge Graph)를 출시하며 검색어를 단순한 문자열이 아닌 개념으로 이해하기 시작한 것이죠.
당시 구글 검색 담당 부사장 아밋 싱할(Amit Singhal)은 이를 "Things, Not Strings"라는 한 문장으로 설명했습니다. 검색어를 단순한 문자 조합이 아니라, 실제 의미를 가진 개념으로 이해하겠다는 선언이었죠. 이를 위해 구글은 사람·장소·사물 같은 엔티티를 1,500개의 유형과 3만 5,000개의 관계로 구조화했습니다. 그 결과 우리가 매일 보는 구글 검색 결과 화면에는 링크 목록 대신 인물 정보, 관련 사건, 연관 개념이 정리된 지식 패널이 등장하게 됐죠. 2012년 출시 당시 5억 개의 엔티티와 35억 개의 사실 정보로 시작한 지식 그래프는 폭발적으로 성장하여, 현재는 50억 개 이상의 엔티티와 5,000억 개 이상의 사실 정보를 다루고 있습니다.
3. 삼성 SDS
삼성SDS는 자사 생성형 AI 기반 협업 소프트웨어 '브리티웍스'에 온톨로지를 적용하고 있습니다. 브리티웍스는 한 조직원이 여러 개의 에이전트를 사용할 수 있는 환경을 설계하고 있는데요. 문제는 각 에이전트가 사용자 정보와 업무 맥락을 공유받지 못한 채 독립적으로 작동하면, 오히려 생산성 향상에 방해가 될 수 있다는 것입니다.
삼성SDS는 이를 극복하기 위해 사내 인트라넷 '녹스(Knox)'의 방대한 데이터를 지식 그래프로 구조화하고, 협업 플랫폼 '브리티웍스'에 '개인별 온톨로지' 기술을 결합하고 있습니다. 목표는 사용자의 개별 업무 맥락과 의도를 깊이 이해하는 초개인화 AI 비서를 구현하는 것입니다. 회사 전체 업무와 데이터를 온톨로지로 통합해 사람, 조직, 업무, 문서, 시스템 사이의 관계를 AI가 이해할 수 있도록 만드는 것이죠. 단순 검색과 요약을 넘어 결재, 보고, 업무 흐름 자동화까지 한 번에 실행할 수 있는 것입니다.
4. 마이스터즈
가전 설치·수리 업계에서는 수십 년간 현장 경험이 엔지니어 개인의 머릿속에만 쌓여왔습니다. 제품 수리법, 교체 주기 등 다양한 노하우가 조직의 자산이 아닌 개인의 암묵지로 남아 있었죠. 구조화된 적이 없으니 데이터가 될 수 없었고, 데이터가 없으니 AI도 작동할 수 없었습니다.
마이스터즈는 이런 블루칼라 현장의 암묵지를 걷어내고 있습니다. 이를 위해 2019년부터 가전 설치·수리 현장의 모든 서비스 과정을 데이터로 기록하며 독자적인 블루칼라 온톨로지를 구축해 오고 있는데요. 주문 배정부터 업무 수행, 검증, 정산에 이르는 전 과정에서 발생하는 제품, 엔지니어, 서비스 카테고리, 지역에 대한 방대한 데이터를 축적하고 상호 연결하는 것이죠. 이렇게 구축된 데이터 기반 온톨로지를 통해 엔지니어를 단순히 파견하는 것에서 그치지 않고, 고객 문의 접수부터 최종 해결까지 전 과정을 책임지는 서비스 운영체제를 만드는 것이 목표입니다.
마이스터즈, 블루칼라의 온톨로지를 꿈꾸다
온톨로지는 결국 현실을 데이터로 번역해 조직 전체가 같은 언어로 움직이게 만드는 작업입니다. 팔란티어는 흩어진 데이터를 하나로 묶었고, 구글은 검색어에 의미를 부여했으며, 삼성SDS는 여러 AI 에이전트가 같은 맥락 위에서 일하도록 만들고 있습니다. 이들이 온톨로지를 구축하는 이유는 하나입니다. 데이터를 쌓는 것을 넘어, 그 데이터가 실제 판단과 운영으로 이어지게 만드는 것이죠.
그러나 블루칼라 현장은 아직도 데이터 대신 사람의 경험에만 의존하고 있습니다. 여기에는 큰 위험이 있습니다. 수십 년의 노하우가 엔지니어 개인의 경험으로만 남아, 사람이 떠나면 지식도 함께 사라진다는 것이죠. 이 현장의 언어를 시스템이 이해할 수 있는 구조로 바꾸는 순간, 개인의 경험은 비로소 조직의 자산이 됩니다.
단순한 데이터의 축적을 넘어, 서비스 전 과정의 효율을 극대화하고 고도화된 예측 및 성과 분석을 가능하게 만드는 것. 이것이 마이스터즈가 꿈꾸는 블루칼라의 온톨로지입니다. 마이스터즈가 만드는 블루칼라의 미래가 궁금하다면, 아래 링크를 클릭해 보세요.

